I don't do supercomputing. I don't do Photoshop. My media processing is limited to MP3 playback, and one MP3 encoding tool (with very particular parameters). My two time sink games are Diablo 2 and Counter-Strike, which aren't 3D floating point monsters.
I care a lot more about integer code. Stuff like web browsers, mail readers, editors---heck, anything with a lot of cycles going into the interface. And I'm a hacker too, so I care about shells, compilers, interpreters, emulators, network servers, and so on.
I don't have a good way of measuring UI performance, especially across platforms. But I do have a number of big "rebuild everything" compile tasks that I want to be fast. Almost all of them are hosted on Linux, which is good because Linux runs on most hardware I run into. While these tasks are no substitute for a broad, principled benchmark like SPEC CPU2000, they do exercise many different features and can serve as a rough proxy for integer performance. And besides, I already had my tasks ready and packaged :-)
(Update: added cross-only totals and bogohurts numbers; the implications weren't clear enough in the summary tables.)
| install-egcs | install-glibc | cross-gcc | total | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Machine | wall | (sec) | user | sys | cpu | wall | (sec) | user | sys | cpu | wall | (sec) | user | sys | cpu | wall | user |
| bandwagon | 6:14 | 374 | 328 | 32 | 96% | 7:25 | 445 | 352 | 82 | 97% | 2:29 | 149 | 137 | 10 | 98% | 968 | 817 |
| family-values | 4:36 | 276 | 219 | 31 | 90% | 5:35 | 335 | 242 | 71 | 93% | 1:38 | 98 | 85 | 10 | 97% | 709 | 546 |
| style-over-substance | 11:53 | 713 | 619 | 84 | 98% | 13:15 | 795 | 548 | 235 | 98% | 3:59 | 239 | 207 | 28 | 98% | 1747 | 1374 |
| ohlfs | 8:51 | 531 | 464 | 64 | 99% | 9:47 | 587 | 399 | 182 | 98% | 2:59 | 179 | 157 | 22 | 99% | 1297 | 1020 |
| Machine | CPU family | MHz | install-egcs | install-glibc | cross-gcc | total | cross
only |
"P3
Bogohurts" |
"Cross P3
Bogohurts" |
||
| bandwagon | P3 | 733 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 733 | 733 | ||
| family-values | Athlon | 1200 | 1.36 | 1.33 | 1.52 | 1.37 | 1.37 | 1001 | 1006 | ||
| style-over-substance | G3 | 450 | 0.52 | 0.56 | 0.62 | 0.55 | 0.57 | 406 | 421 | ||
| ohlfs | G4 | 533 | 0.70 | 0.76 | 0.83 | 0.75 | 0.78 | 547 | 568 |
| Machine | CPU family | MHz | install-egcs | install-glibc | cross-gcc | total | cross
only |
"P3
Bogohurts" |
"Cross P3
Bogohurts" |
||
| bandwagon | P3 | 733 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 733 | 733 | ||
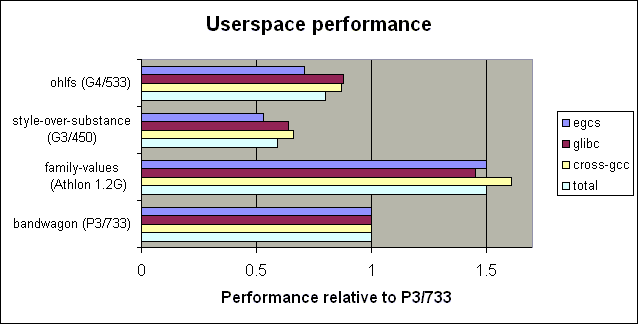
| family-values | Athlon | 1200 | 1.50 | 1.45 | 1.61 | 1.50 | 1.50 | 1097 | 1096 | ||
| style-over-substance | G3 | 450 | 0.53 | 0.64 | 0.66 | 0.59 | 0.65 | 436 | 475 | ||
| ohlfs | G4 | 533 | 0.71 | 0.88 | 0.87 | 0.80 | 0.88 | 587 | 645 |
Total CPU utilization as a percentage reports what part of the wall clock time was actually spent directly working on this process, either in user space or in the kernel; this will be less than 100% because of other running processes or waiting for disk I/O.
I don't entirely trust the kernel's CPU time accounting; it's had problems in the distant past. The wall clock times should be trustworthy, though.
The bottom two tables summarize the raw data from the first table. I decided to use bandwagon, a P3/733, as a baseline. "cross-only" is the total of the two tests that should be roughly equal work on any architecture: install-glibc and cross-gcc. See below for details.
In addition to relative performance metrics, I've added a bogus clock speed rating. It's just the machine's performance multipled by the baseline machine's 733MHz clock speed. It suggests how fast a Pentium 3 you'd need to equal the speed of the machine being tested. It's bogus in a lot of different ways; for instance I doubt a P3/850 would reach a score of 850, and a P3/450 should do better than a 450. But it's fun to pretend performance scales linearly with clock speed....
Oh yes. I've run these benchmarks multiple times on each machine. The results were easily within 3% of the original each time. Really, I should have averaged them all but it didn't seem worth it with so little variation.
In general, timing native builds across platforms does not measure equal work. Some architectures require more optimization work to be done at compile time in return for improved run time performance. The only people who should care about native build performance are developers who are planning to work directly on the platform. (Yes, that's me sometimes.)
Instead of compiling source to native binaries, we can compile source to binaries for a single chosen platform. If every platform under consideration produces identical (say) SPARC object files, the same amount of work has gone into their production. (This is the basis of benchmark 176.gcc in SPEC CPU2000. Shame SPEC benchmarks aren't free.)
Compiling for a processor other than the host machine is called cross-compiling, and it's most often seen in the embedded world. I work on the Linux VR project, an ongoing port of the Linux kernel to embedded MIPS processors such as the NEC VR41xx series and Toshiba TX39xx series. I mostly work with the VTech Helio and Agenda VR3 PDAs. Most people don't have powerful little-endian MIPS-based machines available, so most development is performed on standard desktop Linux boxes and cross-compiled to produce MIPS binaries for the devices.
I've done work on the compiler/assembler/linker toolchain itself for Linux VR devices, as well as on the GNU C library. Often changes to one part of the system would require a rebuild of everything from scratch; waiting around for my 300MHz Cyrix box to chug through at all gave me a lot of time to contemplate performance and upgrades....
It would be nice to have some easy benchmarks that don't depend on Linux. This would remove the inevitable complaints that "Mac hardware was designed to run Mac OS!"/"Sun hardware was designed to run Solaris!" etc. I think a really big, complicated LaTeX document could be a good start; TeX is available for most platforms and operating systems and produces identical output everywhere.
No special compiler options are given. Most of the binaries that ship with the Debian system are built like that. Also, shipped binaries have to run on every flavor of the processor family, so you can't use stuff like -march=i686 because some of the opcodes aren't available on other x86 implementations. Quick tests show various optional G3 optimizations in gcc don't seem to help much, and AltiVec is mostly useless for these kinds of programs. (I haven't decided how strongly I believe in this no-flags rule.)
I don't care about non-gcc compilers. I don't get to use them. It seems like few people use non-default compilers to build apps, which is why I'm not that excited about the fantastic numbers Intel's compiler gets---most people are still using VC++... And remember, Mac OS X ships with gcc as the compiler, so the generated code quality should be comparable. If Apple's gcc has PPC optimizations the FSF tree doesn't have, well, I'll get them when Apple contributes them back to the FSF.
The Linux kernel on PPC probably receives less tuning than the x86 kernel. Counting userspace times should compensate for that somewhat.
This measures native builds. It only should be of interest to people who are planning to do development directly on the platform.
This test is the same amount of work on any platform.
glibc has a complex build system; just the make process accounts for a significant portion of execution time. There are lots of compiles of little fifteen line files with a single function in them. Lots of shell stuff kicked off too. The kernel does a lot of work.
This test is the same amount of work on any platform.
gcc's build process, although still complicated, is closer to the way most applications are built. Most of the CPU goes to the compiler.
style-over-substance is an iMac DV+; a G3/450 with 320M of RAM.
ohlfs is a Power Mac G4; a G4/533 with 512M of RAM. It's actually a dual processor box, but only 1 CPU is used because it runs a uniprocessor kernel. Out of the box, the build tests do not really take advantage of a second processor, and there are some performance penalties just for running a multiprocessor kernel; it seemed more fair to compare it as a uniprocessor. I need to do some more work to get meaningful dual processor numbers.
family-values is a no-name PC; an Athlon 1.2GHz (200MHz external) on an ASUS A7V with 256M of RAM. Its IDE interface is crippled (long story) and only manages 3MB/sec in PIO mode---this box eats a lot of overhead talking to disk.
(Tests on decoy (Celeron 450) and red-herring (P2/266) are blocking on OS upgrades.)
The PPC machines spend a lot more time in the kernel compared to the x86 boxes. (Or at least it's accounted that way.) I don't understand this, and that's the biggest reason I'm including usertime-only tables. Perhaps the 2.4 kernels will do better and reduce the wall clock time.
bandwagon was $500 with shipping from the Dell refurb store; it would cost approximately $750 delivered, new. family-values is on loan to me; it was assembled assembled by mwave.com. You could rebuy it for ~$800 today. style-over-substance came from eBay, and would cost at least $900 new---that's the cheapest Mac you can buy. ohlfs doesn't belong to me; a stripped single-CPU version costs $2070 at the Apple store. Let's ignore memory prices. Also, I've got enough monitors, graphics cards, CD-ROM drives, operating system licenses, and other parts attached to my network that I don't *want* even the options bundled with most of these boxes.
So here's the $ per bogohurts numbers for userspace performance:
| Machine | Processor | Approximate
price |
Userspace
$/bogohurts |
| bandwagon | P3/733 | $750 | $1.02 |
| family-values | Athlon 1200 | $800 | $0.72 |
| style-over-substance | G3/450 | $900 | $2.06 |
| ohlfs | G4/533 | $2070 | $3.53 |
(Orginally I wasn't going to put this table in, but somebody pointed out that I was already going to generate many flames, so I might as well get in all the iffy tables.)
Maximizing bogohurts/$ is not the goal of most computer buyers. family-values was designed specifically to 0wn the crosscompile workload for low dollars, which is why it has dual 45G IBM IDE drives, no keyboard or mouse, and no CD-ROM drive. It also runs quite hot, and its IDE configuration problems sucked up a bunch of my time.
style and ohlfs run Mac OS X a zillion times faster than the x86 boxes, giving an infinite advantage in price/performance at that workload. That's why I bought that iMac.
One of the motivations for these benchmarks was that I got sick of all the people claiming that the PPC enjoyed vast performance advantages over equiv clocked x86 processors. Claims like "most powerful laptop in the world" and "twice as fast as a Pentium" turn off some of Apple's potential customers, even if the claims are properly qualified down in the fine print. "This is the only hardware allowed to run Mac OS X" was good enough to make me a customer.
Before I started looking at this, my gut feeling was that PPC should be ~20% faster than equiv clocked Pentiums. Now my gut feeling is that gcc's code generator kinda sucks.